O guia de não iniciantes para sincronizar dados com o Rsync
O protocolo rsync pode ser bem simples de usar para tarefas comuns de backup / sincronização, mas alguns de seus recursos mais avançados podem surpreendê-lo. Neste artigo, mostraremos como até mesmo os maiores colecionadores de dados e entusiastas de backup podem utilizar o rsync como uma solução única para todas as suas necessidades de redundância de dados.
Aviso: Somente Geeks avançados
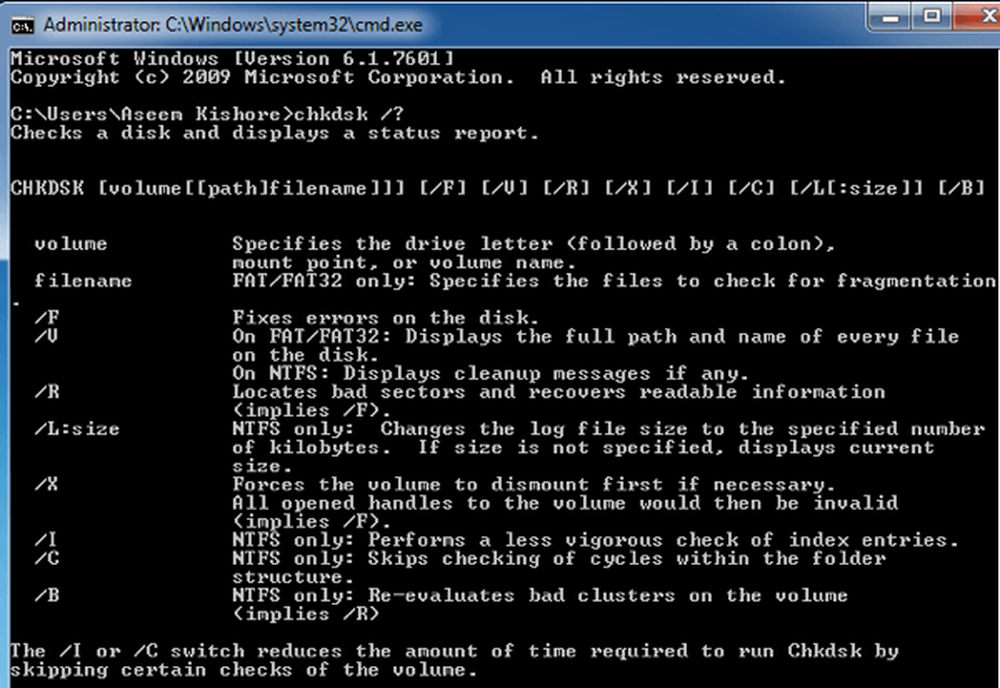
Se você está sentado pensando “O que diabos é rsync?” Ou “Eu uso apenas o rsync para tarefas realmente simples”, você pode querer verificar nosso artigo anterior sobre como usar o rsync para fazer backup de seus dados no Linux, o que dá uma introdução ao rsync, guia você pela instalação e mostra suas funções mais básicas. Uma vez que você tenha uma compreensão firme de como usar o rsync (honestamente, não é tão complexo) e esteja confortável com um terminal Linux, você está pronto para seguir este guia avançado.
Executando o rsync no Windows
Primeiro, vamos colocar nossos leitores do Windows na mesma página dos nossos gurus do Linux. Embora o rsync seja construído para rodar em sistemas do tipo Unix, não há motivo para que você não consiga usá-lo com a mesma facilidade no Windows. O Cygwin produz uma maravilhosa API do Linux que podemos usar para rodar o rsync, então vá para o site deles e baixe a versão de 32 ou 64 bits, dependendo do seu computador..
A instalação é direta; você pode manter todas as opções com seus valores padrão até chegar à tela "Selecionar Pacotes".
Agora você precisa fazer os mesmos passos para o Vim e o SSH, mas os pacotes vão parecer um pouco diferentes quando você for selecioná-los, então aqui estão algumas capturas de tela:
Instalando o Vim:
Instalando o SSH:
Depois de selecionar esses três pacotes, continue clicando em próximo até concluir a instalação. Então você pode abrir o Cygwin clicando no ícone que o instalador colocou na sua área de trabalho.
Comandos rsync: simples ao avançado
Agora que os usuários do Windows estão na mesma página, vamos dar uma olhada em um simples comando rsync e mostrar como o uso de alguns switches avançados pode rapidamente torná-lo complexo.
Vamos dizer que você tem um monte de arquivos que precisam de backup - quem não faz hoje em dia? Você conecta seu disco rígido portátil para fazer backup dos arquivos de seus computadores e emitir o seguinte comando:
rsync -a / home / geek / arquivos / / mnt / usb / files /
Ou a maneira como ficaria em um computador Windows com o Cygwin:
rsync -a / cygdrive / c / arquivos / / cygdrive / e / files /
Bastante simples, e nesse ponto realmente não há necessidade de usar o rsync, já que você pode simplesmente arrastar e soltar os arquivos. No entanto, se o seu outro disco rígido já tiver alguns dos arquivos e precisar apenas das versões atualizadas e dos arquivos que foram criados desde a última sincronização, esse comando é útil, pois envia somente os novos dados para o disco rígido. Com arquivos grandes e especialmente transferindo arquivos pela Internet, isso é um grande negócio.
Fazer o backup de seus arquivos em um disco rígido externo e manter o disco rígido no mesmo local do computador é uma péssima ideia, então vamos dar uma olhada no que seria necessário para começar a enviar seus arquivos pela Internet para outro computador ( um que você alugou, um membro da família, etc).
rsync -av --delete -e 'ssh -p 12345' / home / geek / arquivos / [email protected]: / home / geek2 / files /
O comando acima enviaria seus arquivos para outro computador com um endereço IP de 10.1.1.1. Ele excluiria arquivos estranhos do destino que não existem mais no diretório de origem, geraria a saída dos nomes dos arquivos para que você tenha uma ideia do que está acontecendo e faça o rsync do túnel através do SSH na porta 12345.
o -a -v -e --delete switches são alguns dos mais básicos e comumente usados; você já deve saber muito sobre eles se estiver lendo este tutorial. Vamos falar sobre alguns outros switches que às vezes são ignorados, mas incrivelmente úteis:
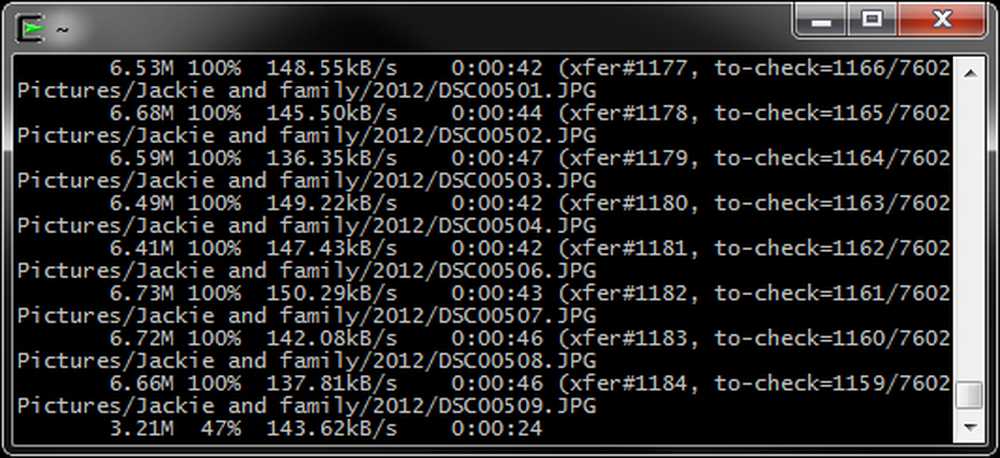
--progresso - Essa opção nos permite ver o progresso da transferência de cada arquivo. É particularmente útil ao transferir arquivos grandes pela Internet, mas pode gerar uma quantidade absurda de informações ao transferir arquivos pequenos por uma rede rápida..
Um comando rsync com o --progresso alternar como um backup está em andamento:
--parcial - Este é outro switch que é particularmente útil ao transferir arquivos grandes pela Internet. Se o rsync for interrompido por algum motivo no meio de uma transferência de arquivos, o arquivo parcialmente transferido é mantido no diretório de destino e a transferência é retomada de onde parou quando o comando rsync for executado novamente. Ao transferir arquivos grandes pela internet (digamos, alguns gigabytes), não há nada pior do que ter uma segunda interrupção na Internet, tela azul ou erro humano atrapalhar a transferência de arquivos e ter que começar tudo de novo.
-P - este interruptor combina --progresso e --parcial, então use-o em vez disso e ele tornará seu comando rsync um pouco mais limpo.
-z ou --comprimir - Essa opção fará com que os dados do arquivo de compactação rsync sejam transferidos, reduzindo a quantidade de dados que deve ser enviada para o destino. Na verdade, é uma opção bastante comum, mas está longe de ser essencial, apenas beneficiando você em transferências entre conexões lentas e não faz nada para os seguintes tipos de arquivos: 7z, avi, bz2, deb, g, z iso, jpeg, jpg, mov, mp3, mp4, ogg, rpm, tbz, tgz, z, zip.
-h ou --legível para humanos - Se você estiver usando o --progresso mudar, você definitivamente vai querer usar este também. Ou seja, a menos que você queira converter bytes em megabytes rapidamente. o -h O switch converte todos os números de saída em formato legível, para que você possa realmente entender a quantidade de dados sendo transferidos.
-n ou --funcionamento a seco - Essa opção é essencial para saber quando você está primeiro escrevendo seu script rsync e testando-o. Ele realiza uma execução de teste, mas na verdade não faz nenhuma alteração - as alterações que ainda estão sendo feitas ainda são exibidas normalmente, portanto, você pode ler tudo e verificar se está tudo bem antes de colocar o script em produção.
-R ou --relativo - Essa opção deve ser usada se o diretório de destino ainda não existir. Usaremos essa opção posteriormente neste guia para que possamos criar diretórios na máquina de destino com registros de data e hora nos nomes das pastas.
--excluir-de - Essa opção é usada para vincular a uma lista de exclusão que contém caminhos de diretório dos quais você não deseja fazer backup. Só precisa de um arquivo de texto simples com um diretório ou caminho de arquivo em cada linha.
--incluir-de - Igual a --excluir-de, mas ele se vincula a um arquivo que contém diretórios e caminhos de arquivos dos quais você deseja fazer backup.
--Estatísticas - Não é realmente uma opção importante, mas se você for um administrador de sistema, pode ser útil saber as estatísticas detalhadas de cada backup, para poder monitorar a quantidade de tráfego que está sendo enviada pela rede e.
--arquivo de log - Isso permite enviar a saída rsync para um arquivo de log. Nós definitivamente recomendamos isso para backups automatizados em que você não está lá para ler a saída. Sempre forneça os arquivos de log uma vez no seu tempo livre para garantir que tudo esteja funcionando corretamente. Além disso, é uma mudança crucial para o uso de um administrador de sistema, então você não fica imaginando como seus backups falharam enquanto você deixava o estagiário responsável.
Vamos dar uma olhada no nosso comando rsync agora que temos mais alguns switches adicionados:
rsync -avzhP --delete --stats --log-file = /home/geek/rsynclogs/backup.log --exclude-from '/home/geek/exclude.txt' -e 'ssh -p 12345' / home / geek / files / [email protected]: / home / geek2 / files /
O comando ainda é bem simples, mas ainda não criamos uma solução de backup decente. Embora nossos arquivos estejam em dois locais físicos diferentes, esse backup não nos protege de uma das principais causas de perda de dados: erro humano.
Backups de instantâneos
Se você acidentalmente excluir um arquivo, um vírus corromper qualquer um dos seus arquivos, ou outra coisa acontecer por meio da qual seus arquivos são indesejados, e você executar seu script de backup rsync, seus dados de backup serão sobrescritos pelas alterações indesejáveis. Quando isso acontece (não se, mas quando), sua solução de backup não fez nada para protegê-lo da perda de dados.
O criador do rsync percebeu isso e adicionou o --cópia de segurança e --backup-dir argumentos para que os usuários pudessem executar backups diferenciais. O primeiro exemplo no site do rsync mostra um script em que um backup completo é executado a cada sete dias e, em seguida, as alterações nesses arquivos são armazenadas em diretórios separados diariamente. O problema com esse método é que, para recuperar seus arquivos, você precisa recuperá-los sete vezes diferentes. Além disso, a maioria dos geeks executa seus backups várias vezes ao dia, então você pode facilmente ter mais de 20 diretórios de backup diferentes a qualquer momento. Não apenas recuperar seus arquivos agora é uma tarefa difícil, mas até mesmo examinar seus dados de backup pode consumir muito tempo - você precisaria saber a última vez que um arquivo foi alterado para encontrar a cópia de backup mais recente. Além de tudo isso, é ineficiente executar somente backups incrementais semanais (ou, em alguns casos, com menos frequência).
Backups de snapshots para o resgate! Os backups de captura instantânea não são nada além de backups incrementais, mas utilizam hardlinks para manter a estrutura de arquivos da origem original. Isso pode ser difícil em primeiro lugar, então vamos dar uma olhada em um exemplo.
Imagine que temos um script de backup em execução que faz o backup dos nossos dados automaticamente a cada duas horas. Sempre que o rsync faz isso, ele nomeia cada backup no formato: Backup-mês-dia-ano-hora.
Então, no final de um dia típico, teríamos uma lista de pastas em nosso diretório de destino como este:

Ao percorrer qualquer um desses diretórios, você veria todos os arquivos do diretório de origem exatamente como estavam no momento. No entanto, não haveria duplicatas em quaisquer dois diretórios. rsync faz isso com o uso de hardlinking através do --link-dest = DIR argumento.
É claro que, para ter esses nomes de diretórios bem e bem datados, teremos que reforçar um pouco nosso script rsync. Vamos dar uma olhada no que seria necessário para realizar uma solução de backup como essa e, em seguida, explicaremos o script com mais detalhes:
#! / bin / bash
#copy old time.txt para time2.txt
sim | cp ~ / backup / time.txt ~ / backup / time2.txt
#overwrite old time.txt file com nova hora
eco 'data + ”% F-% I% p”'> ~ / backup / time.txt
#fazer o arquivo de log
echo “”> ~ / backup / rsync-'date + ”% F-% I% p” '.
Comando #rsync
rsync -avzhPR - chmod = Du = rwx, Dgo = rx, Fu = rw, Fgo = r - apagar --stats --log-file = ~ / backup / rsync-'data + ”% F-% I% p ''. log --exclude-from '~ / exclude.txt' --link-dest = /home/geek2/files/ 'cat ~ / backup / time2.txt' -e 'ssh -p 12345' / home / geek / files / [email protected]: / home / geek2 / files / 'date + ”% F-% I% p”' /
# não se esqueça de scp o arquivo de log e colocá-lo com o backup
scp -P 12345 ~ / backup / rsync-'cat ~ / backup / time.txt'.log [email protected]: / home / geek2 / arquivos / 'cat ~ / backup / time.txt' / rsync-'cat ~ / backup / time.txt'.log
Isso seria um típico script rsync de instantâneo. Caso o tenhamos perdido em algum lugar, vamos dissecar peça por peça:
A primeira linha do nosso script copia o conteúdo de time.txt para time2.txt. O pipe sim é para confirmar que queremos sobrescrever o arquivo. Em seguida, pegamos a hora atual e colocamos no time.txt. Esses arquivos serão úteis depois.
A próxima linha cria o arquivo de log rsync, nomeando-o como rsync-date.log (onde date é a data e a hora reais).
Agora, o comando rsync complexo que estamos lhe alertando:
-avzhPR, -e, --delete, --stats, --log-file, --exclude-from, --link-dest - Apenas os interruptores de que falamos anteriormente; role para cima se você precisar de uma atualização.
--chmod = Du = rwx, Dgo = rx, Fu = rw, Fgo = r - Estas são as permissões para o diretório de destino. Como estamos criando este diretório no meio do nosso script rsync, precisamos especificar as permissões para que o usuário possa gravar arquivos nele.
O uso de comandos date e cat
Vamos examinar cada uso dos comandos date e cat dentro do comando rsync, na ordem em que eles ocorrem. Nota: estamos cientes de que há outras maneiras de realizar essa funcionalidade, especialmente com o uso de variáveis de declaração, mas para o propósito deste guia, decidimos usar este método.
O arquivo de log é especificado como:
~ / backup / rsync-'date + ”% F-% I% p” '.
Alternativamente, poderíamos ter especificado como:
~ / backup / rsync-'cat ~ / backup / time.txt'.log
De qualquer maneira, o --arquivo de log comando deve ser capaz de encontrar o arquivo de log datado criado anteriormente e gravar nele.
O arquivo de destino do link é especificado como:
--link-dest = / home / geek2 / files / 'cat ~ / backup / time2.txt'
Isso significa que o --link-dest comando recebe o diretório do backup anterior. Se estamos executando backups a cada duas horas, e são 4:00 da tarde no momento em que executamos este script, então o --link-dest O comando procura pelo diretório criado às 2:00 PM e transfere apenas os dados que foram alterados desde então (se houver).
Para reiterar, é por isso que time.txt é copiado para time2.txt no começo do script, então o --link-dest comando pode referenciar esse tempo depois.
O diretório de destino é especificado como:
[email protected]: / home / geek2 / files / 'date + ”% F-% I% p”'
Esse comando simplesmente coloca os arquivos de origem em um diretório que possui um título da data e hora atuais.
Por fim, garantimos que uma cópia do arquivo de log seja colocada dentro do backup.
scp -P 12345 ~ / backup / rsync-'cat ~ / backup / time.txt'.log [email protected]: / home / geek2 / arquivos / 'cat ~ / backup / time.txt' / rsync-'cat ~ / backup / time.txt'.log
Usamos cópia segura na porta 12345 para pegar o log rsync e colocá-lo no diretório correto. Para selecionar o arquivo de log correto e garantir que ele fique no lugar certo, o arquivo time.txt deve ser referenciado por meio do comando cat. Se você está se perguntando por que nós decidimos usar o comando time.txt em vez de apenas usar o comando date, é porque muito tempo poderia ter acontecido enquanto o comando rsync estava rodando, então para ter certeza de que temos o momento certo, o documento de texto que criamos anteriormente.
Automação
Use o Cron no Linux ou o Agendador de Tarefas no Windows para automatizar seu script rsync. Uma coisa que você deve ter cuidado é ter certeza de que você encerra qualquer processo de rsync atualmente em execução antes de continuar com um novo. O Agendador de Tarefas parece fechar as instâncias já em execução automaticamente, mas, para o Linux, você precisará ser um pouco mais criativo.
A maioria das distribuições Linux pode usar o comando pkill, portanto, certifique-se de adicionar o seguinte ao início do seu script rsync:
pkill -9 rsync
Encriptação
Não, ainda não terminamos. Finalmente, temos uma solução de backup fantástica (e gratuita!), Mas todos os nossos arquivos ainda são suscetíveis a roubo. Espero que você esteja fazendo o backup de seus arquivos em algum lugar a centenas de quilômetros de distância. Não importa o quão seguro seja esse lugar distante, roubo e hacking sempre podem ser problemas.
Em nossos exemplos, encapsulamos todo o nosso tráfego rsync por meio do SSH, o que significa que todos os nossos arquivos são criptografados enquanto estão em trânsito para o destino. No entanto, precisamos garantir que o destino seja tão seguro quanto. Tenha em mente que o rsync só criptografa seus dados à medida que eles são transferidos, mas os arquivos ficam abertos quando chegam ao destino.
Um dos melhores recursos do rsync é que ele transfere apenas as alterações em cada arquivo. Se você tiver todos os seus arquivos criptografados e fizer uma pequena alteração, o arquivo inteiro terá que ser retransmitido como resultado da criptografia, randomizando completamente todos os dados após qualquer alteração..
Por esse motivo, é melhor / mais fácil usar algum tipo de criptografia de disco, como o BitLocker para Windows ou o dm-crypt para Linux. Dessa forma, seus dados são protegidos em caso de roubo, mas os arquivos podem ser transferidos com o rsync e sua criptografia não prejudicará seu desempenho. Existem outras opções disponíveis que funcionam de forma semelhante ao rsync ou até mesmo implementam alguma forma dele, como o Duplicity, mas elas não possuem alguns dos recursos que o rsync tem a oferecer.
Depois de configurar seus backups de snapshots em um local externo e criptografar seus discos rígidos de origem e destino, dê um tapinha nas costas para dominar o rsync e implementar a solução de backup de dados mais à prova de falhas possível.